
OML - Research
A Warning System for COVID-19 Prevention Measures
As the pandemic introduced new protective measures into our daily lives, we recognized the need for AI systems to adapt to these changes. Thus, we focused on exploring and proposing methods to enhance the capabilities of the learning systems and their adaptation to new challenges. In this context, we developed a method (Eyiokur et al. 2021) that combines three primary preventive measures: social distancing, proper use of face masks, and face-hand interaction detection. This led to the establishment of a comprehensive warning system that simultaneously considers these critical aspects. To support our research, we introduced two new extensive datasets: the ISL-UFMD dataset, one of the largest face mask datasets containing unconstrained images from the real world with various variations and instances of improper mask use, and the ISL-UFHD dataset, the first unconstrained dataset for face-hand interaction (Eyiokur et al. 2021). These datasets played a crucial role in training and evaluating various Convolutional Neural Network (TDNN/CNN) models.
To explore the further challenges and new approaches related to this pandemic and its consequences, we organized a workshop titled 'The International Workshop on Face and Gesture Analysis for COVID-19 (FG4COVID19)' at FG 2021 (https://fg4covid19.github.io/). Subsequently, we extensively discussed the topic in our survey (Eyiokur et al. 2022).
Link to the paper
Scene Analysis and Image Enhancement with Exposure Correction
Scene analysis for robots is a crucial task for effectively understanding and navigating complex environments. This capability enables robots to make the right decisions and execute tasks with increased precision. Finally, it allows robots to adapt to different environments. Our focus is on scene/object manipulation for human-robot interaction. Scene/object manipulation is beneficial for robots (and other systems) when generating training data with slight variations or depicting the start and end phases of an action. With the ability to add a new object or modify/remove an existing object, we can create the desired data using an arbitrary scene. This data is also helpful in learning a new object incrementally or enhancing the recognition capacity of an object by providing varied images. To achieve this, we employed a method of conditional image editing using conditional Generative Adversarial Nets (GANs), which takes a text description (e.g., add a white cup, make the color of the bottle green), an arbitrary image, and a mask image. Thus, the masked area of the given input image is modified with respect to the provided text input.
Another crucial task for human-robot interaction is the segmentation of individuals. The fundamental task is to segment people in the scene, enabling robots to specifically identify the boundaries of individuals within an image or video. This is useful for robots in various ways, such as estimating human posture, recognizing activities, image and video processing, monitoring, and security, among others. Additionally, it allows distinguishing the person from the background. We focused on the task of person matting. The main difference is that, instead of segmenting the person with a binary map (assigning a binary label as foreground or background to each pixel), we predicted an alpha map assigning a value between 0 and 1 to each pixel of the image. This value describes how much the pixel belongs to the foreground (namely the person in this task), as some parts of a person are not always completely opaque (such as hair, or clothing). For this, we proposed a GAN-based approach (Yaman, Ekenel, and Waibel 2022) that predicts an alpha map for person matting.
The quality of an image directly or indirectly affects the accuracy or robustness of a computer vision task. To this end, one of the most critical attributes of an image is its exposure. Sometimes, exposure errors can occur for various reasons, such as incorrect shutter speed, a large or small aperture, high or low ISO sensitivity, or challenging lighting conditions in the environment. Particularly, there are two different exposure errors: overexposure and underexposure. Exposure errors in images can substantially affect visual quality, leading to reduced contrast and diminished visibility of content. These errors sometimes result in misclassifications or incorrect recognition during dialogue and interaction with AI systems. To address this issue, we introduced an end-to-end exposure correction model (Eyiokur, Yaman, Ekenel, and Waibel 2022) to handle both underexposure and overexposure errors with a unified approach. When there is no exposure error in the image, our model is capable of preserving the original exposure settings without making any changes.
Verbalization of Episodic Memory from Robotic Experiences and Egocentric Vision
We developed a system that allows the robot to report on its past experiences using natural language. The robot is therefore able to communicate its experiences to people by answering questions about its history. For example, imagining a future household robot that carries out work in the house independently and without supervision, the user will have an interest in what tasks the robot has completed and, in particular, what problems have arisen when they return. The system is based on a neural network architecture and consists of an experience encoder that processes the multimodal experience data recorded by the robotic system, a speech encoder that receives the input texts, and a speech decoder that generates the natural language output. To train the system, a dataset was created using the ArmarX robot simulation. For evaluation purposes, simulated recordings and recordings of the real robot were combined with questions and answers generated both procedurally and by human annotators. The quantitative results showed a rate of 57% of correctly answered questions in short experience sequences.
The task of verbalizing robot experiences was later generalized to the very related task of logging someone's daily experience and later answering questions about it. For example, one can imagine wearing a “smart glass” or a similar device in the future that continuously tracks activities from an egocentric perspective. If you ask yourself at a later point: “Where did I leave my keys?”, the glasses should understand the question and answer it accordingly in order to provide support. This requires the input data (particularly video) to be continuously analyzed so that answering the question can be done quickly, rather than having to search through hours of video data first. To address this problem, a new task called Episodic Memory Question Answering was first introduced, a dataset was collected and published that enables the question-answering task on egocentric video data, and finally, baseline results were presented in a quantitative evaluation. The relatively low scores (max. 7.6 BLEU, 10.3% exact matches) even from existing state-of-the-art models demonstrate the enormous challenge posed by the new data set and encourage further research.
Further information is provided in the published paper and a video on the subject.
Error correction detection and error correction
We developed an error correction component that allows sentences to be corrected via natural language. This is an essential interaction between the user and the system to correct and learn from mistakes. The component can identify if a user's statement is an error correction to the previous one, and if so, the error correction is used to correct the mistake. For the test dataset created for the project with real data, an error correction can be detected in 88.49% of the cases. The recall, that no error correction is available, is 99.90%. This is a good feature as it’s better to not correct a mistake than to correct an already correct statement. In 71.98% of the cases, the error correction can be successfully integrated and the extraction of the reparandum (faulty phrase) and repair (corrected phrase) pairs is correct. The entire system comprised of error correction detection, error correction, and extraction of the reparandum and repair pairs is correct in 77.81% of the cases. The extracted reparandum and repair pairs are used for learning, for example, the automatic speech recognition system uses the pairs to add new words. In this video, you can see the error correction embedded in a demo website.
To implement pointing gestures (Constantin et al. 2023) as additional modalities, along with speech, we have developed a system that calculates a pointing line. All regions-of-interest (RoIs) located on this line are fed into a fine-tuned VL-T5 model along with the natural language text. In our test dataset, the reference RoI is present in the set of suggested RoIs in 58.40% of the cases. In a maximum of three turns, the user's intention could be fulfilled in 49.44% of the cases.
Spatial relations
The goal of our work is to control a robot to perform tabletop manipulation tasks via natural language instructions. Our approach is able to segment objects in the scene, locate the objects referred to in language expressions, solve ambiguities through dialog and place objects in accordance with the spatial relations expressed by the user.
Automatic speech recognition (ASR) systems
One of our research projects focused on incremental learning in the context of automatic speech recognition (ASR) systems, addressing the challenge of limited given labeled data. We demonstrated the adaptation of a trained ASR system using a method called Batch-Weighting, efficiently combining baseline data and new labeled data (Huber et al. 2020). To tackle scenarios with scarce new labeled data, we explored a novel approach where new words could be added to the ASR system without retraining, particularly useful for instances like introducing new names (Huber et al. 2021). With this, we are able to recognize more than 85% of previously unknown words. This technique, combined with additional information from slides or human corrections during a lecture, led to significant improvements (>80% recall) in recognizing new words (Huber, Kumar, and Bojar 2022). However, as a short-term learning solution, this approach had limitations regarding long-term adaptation. To overcome this, we integrated a factorization approach for long-term learning, iterating over multiple learning cycles (Huber and Waibel 2024). The combined approach demonstrated increasing performance (more than 80% recall) for frequently occurring new words while while preserving the general performance of the model. To evaluate and integrate these methods effectively, we integrated the system in practical applications in systems like our Lecture Translator (Huber et al. 2023) and the ARMAR Robotersystem, ensuring robust performance in human-machine interactions. Our study establishes a solid foundation for future research in the field.
Further information on how to start the lecture translator can be found here.
To learn more about the Demo click here.
Incremental Learning in Machine Translation
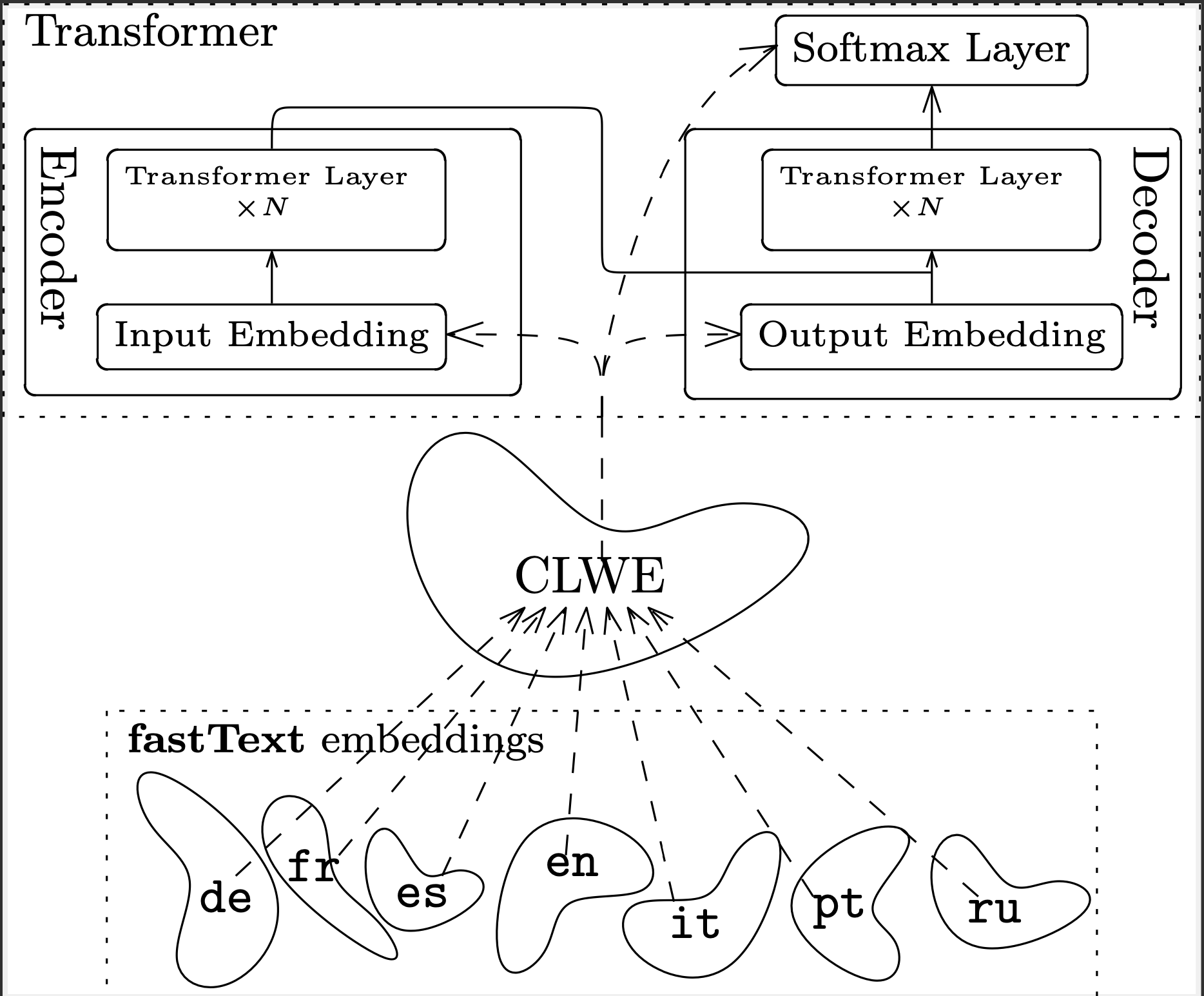
Drawing inspiration from the human approach to acquiring new languages, we propose an incremental learning method for a neural machine translation system. Human learners typically adopt a decoupled approach when studying a foreign language; they may dedicate one day to expanding their vocabulary, and another to mastering grammar or reading comprehension. In the same vein, in a neural machine translation system, we decouple learning the vocabulary representations from learning language syntax.
Whereas traditional supervised training of machine translation systems consists of jointly training word representations and the rest of the neural network on large amounts of translated sentence pairs (so called parallel data), we take a two phase approach to training the network:
first we learn monolingual word representations for each of the languages we want to be able to translate (using traditional Skip-Gram models), and then align these into a common space using a technique called "cross-lingual word-embeddings".
In the second phase we initialize the actual full neural network with these word representations to then train a multilingual translation system to translate between a set of languages using traditional supervised training.
Such a decoupled approach later enables us extend the system by a new language in an incremental and data efficient fashion:
by just learning word representations for that new language and then aligning them into the common vocabulary space of the known languages we enable the system to translate from before unseen languages (albeit with low quality). We may then use this ability to translate from texts in the before unseen language to generate synthetic translation data (e.g. by translating Wikipedia texts), to use them for traditional supervised training. In a fashion known as iterative back-translation we can then iteratively improve the translation quality, while using monolingual data only.
One of the key ideas to this approach is that the neural network in a highly multilingual translation system will learn a well generalized internal sentence representation of its various languages and will thus be more flexible in generalizing to new languages. Such a well generalized representation would allow the system to learn new languages more efficiently than for example a purely bilingual system.
(Value-Based) Reinforcement Learning for Sequence-to-Sequence Models
Generative language models suffer from various problems such as exposure bias, search error, a mismatch between the loss function and the test metrics, and catastrophic forgetting. Motivated by this, we looked at fundamentally different learning approaches. These include reinforcement learning (RL), which would allow us, among other things, to train on any metrics and also directly on human feedback. In the work of Retkowski et al. (Retkowski 2021), we trained sequence models for the first time using value-based RL. A major challenge is the high dimensionality of language problems due to the vocabulary. To counteract this, we combined different techniques, similar to Rainbow DQN (Hessel et al. 2018), and were able to train smaller language models with limited vocabularies that are competitive to supervised-trained models. Foreseeably, however, the scaling problems seem difficult to overcome, which is why we have not deepened the research and have focused on other learning approaches. Nevertheless, a trend is emerging in which reinforcement learning is increasingly being used in language models as part of instruction tuning (Christiano et al. 2017, Brown et al. 2020).
The work was presented at ALA at AAMAS 2021. You can find a recording here, as well as the slides and paper.
Video for more information: here
Slides for more information: here
Paper on the subject: here